KL properties & (cross-)entropy
In this chapter, we'll see how KL divergence can be split into two pieces called cross-entropy and entropy.
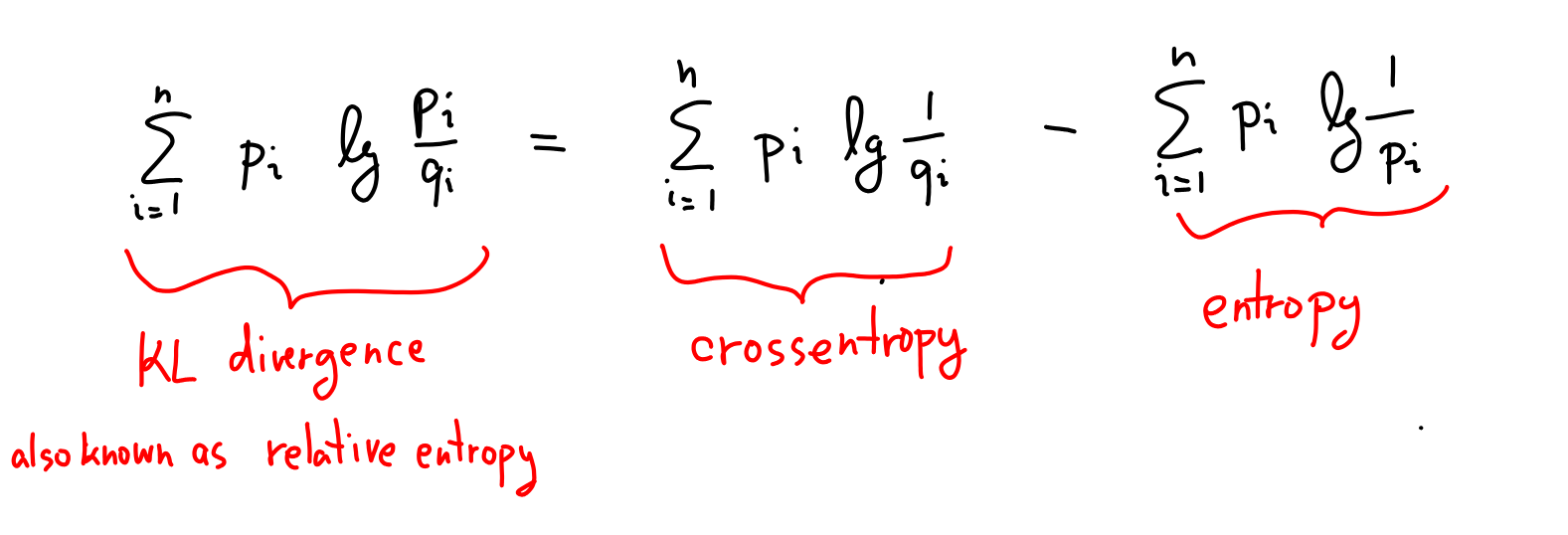 Cross-entropy measures the average surprisal of model on data from . When , we call it entropy.
Cross-entropy measures the average surprisal of model on data from . When , we call it entropy.
KL = cross-entropy - entropy
Quick refresher: In the previous chapter, we saw how KL divergence comes from repeatedly using Bayes' theorem with log-space updating:
Bayes Sequence Explorer (Log Space)
Each step adds surprisals () to track evidence. Last time, we focused on the differences between surprisals to see how much evidence we got for each hypothesis. Our Bayesian detective just keeps adding up these differences.
Alternatively, the detective could add up the total surprisal for each hypothesis (green and orange numbers in the above widget), and then compare overall Total surprisal values. This corresponds to writing KL divergence like this:
These two pieces on the right are super important: is called cross-entropy and is entropy. Let's build intuition for what they mean.
Cross-entropy
Think of cross-entropy this way: how surprised you are on average when seeing data from while modeling it as ?
Explore this in the widget below. The widget shows what happens when our Bayesian detective from the previous chapter keeps flipping her coin. The red dashed line shows cross-entropy—the expected surprisal of the model as we keep flipping the coin with bias . The orange line shows the entropy, which is the expected surprisal when both the model and actual bias are . KL divergence is the difference between cross-entropy and entropy. Notice that the cross-entropy line is always above the entropy line (equivalently, KL divergence is always positive).
If you let the widget run, you will also see a blue and a green curve - the actual surprisal measured by our detective in the flipping simulation. We could also say that these curves measure cross-entropy—it's the cross-entropy between the empirical distribution (the actual outcomes of the flips) and the model (blue curve) or (green curve). The empirical cross-entropies are tracking the dashed lines due to the law of large numbers.
Cross-Entropy Simulator
Bottom line: Better models are less surprised by the data and have smaller cross-entropy. KL divergence measures how far our model is from the best one.
Entropy
The term is a special case of cross-entropy called just plain entropy. It's the best possible cross-entropy you can get for distribution —when you model it perfectly as itself.
Intuitively, entropy tells you how much surprisal or uncertainty is baked into . Even if you know you're flipping a fair coin and hence , you still don't know which way the coin will land. There's inherent uncertainty in that—the outcome still carries surprisal, even if you know the coin's bias. This is what entropy measures.
The fair coin's entropy is bit. But entropy can get way smaller than 1 bit. If you flip a biased coin where heads are very unlikely—say —the entropy of the flip gets close to zero. Makes sense! Sure, if you happen to flip heads, that's super surprising (). However, most flips are boringly predictable tails, so the average surprise gets less than 1 bit. You can check in the widget below that bits per flip. Entropy hits zero when one outcome has 100% probability.
Entropy can also get way bigger than 1 bit. Rolling a die has entropy bits. In general, a uniform distribution over options has entropy , which is the maximum entropy possible for options. Makes sense—you're most surprised on average when the distribution is, in a sense, most uncertain.
Entropy of die-rolling
Relative entropy
KL divergence can be interpreted as the gap between cross-entropy and entropy. It tells us how far your average surprisal (cross-entropy) is from the best possible (entropy). That's why in some communities, people call KL divergence the relative entropy between and . 1
What's next?
We're getting the hang of KL divergence, cross-entropy, and entropy! Quick recap:
In the next chapter, we will do a recap of what kind of properties these functions have and then we are ready to get to the cool stuff.