Fisher information & statistics
In this chapter, we will explain a bit more about how KL divergence connects to statistics. In particular, one of the key statistical concepts is a so-called Fisher information, and we will see how one can derive it using KL divergence.
Fisher information is the limit of KL divergence of close distributions.
The polling problem
In one of our riddles, we have been talking about the problem with polling: If you want to learn the percentage of the vote for one party up to , you need sample about voters.
Polling Error Calculator
Required Sample Size
Quick Scenarios
The law of large numbers
One way to understand why we need samples is via the law of large numbers. This law tells you that if you flip a fair coin times, you typically get around heads. 1. If your coin is biased and heads come out with probability , then the law says you will typically see around heads. If you want to be able to separate the two options, you need the two intervals and to be disjoint, which means that you have to choose such that , i.e., should be at least around .
KL intuition
But I want to offer a complementary intuition for the polling problem. Let's go all the way back to the first chapter where we introduced KL. Our running example was a Bayesian experimenter who wanted to distinguish whether his coin is fair or not fair. If the two distributions to distinguish are and , then the problem of our experimenter gets extremely similar to the problem of estimating the mean up to !
Remember, if we have two very similar distributions, KL between them is going to be positive, but very small. It turns out that
The intuition we should take from this is that each time we flip a coin, we get around " nats of information" about whether the coin is fair or biased by . 2 Intuitively, once we get around 1 nat of information, we begin to be able to say which of the two coins we are looking at. We conclude that the number of trials we need to estimate the bias of a coin should scale like .
Fisher information
The trick with looking at KL divergence between two very similar distributions can be generalized further. Think of a setup where you have a family of distributions characterized by some number. For example:
- biased coins with heads-probability for all .
- gaussians for all .
- gaussians for all .
More generally, think of a set of distributions parameterized by a number .
One of the most basic tasks in statistics is that we have an empirical distribution and we want to find the so that fits the data the best, like below.
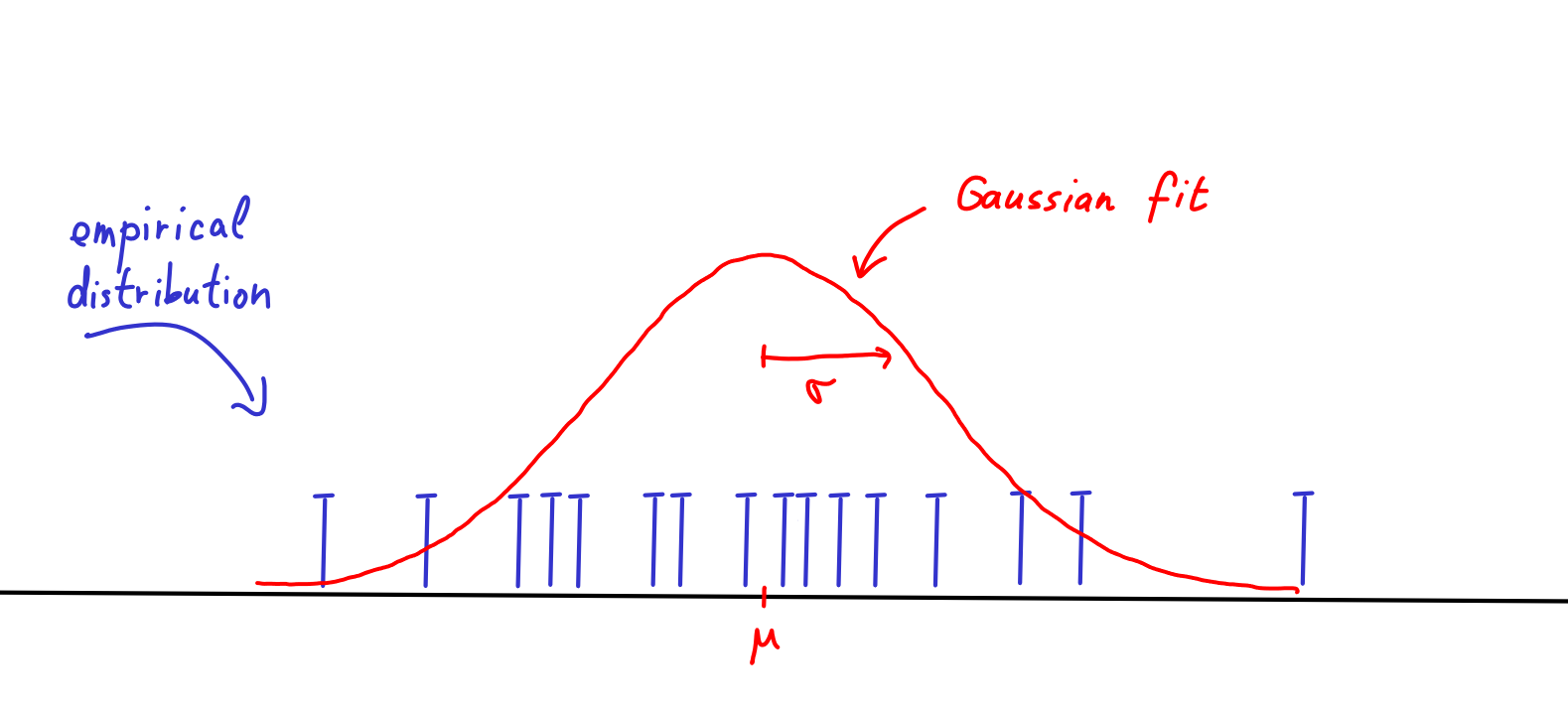
We have already seen this a few times, and we have seen in the chapter about minimizing KL why the maximum likelihood estimators are a reasonable approach to this.
But we can go a bit further -- if we assume that has literally been generated by one of the distributions for some , we may ask how many samples we need to estimate up to additive . Our polling question is just a special case of this more general question.
Our intuition about KL tells us if the data were generated by , to estimate it's key to understand the value of . This is the general (and a bit opaque) formula we thus need to understand:
We will estimate the value of the right-hand side by computing the derivatives and . In particular, we will estimate with the following Taylor-polynomial approximation.
After plugging it in and some calculations 3, we get
for
The term is called Fisher information. Let's not try to understand what this integral mean. The short story is that you can approximate KL divergence of two similar distributions as and can often be computed by integration.
Our KL intuition is telling us that estimating a parameter up to should require about many samples. Let's see what this intuition is saying in some cases:
-
If you want to estimate of a biased coin, . Thus, our KL intuition suggests that estimating the value of (with constant probability) should take about samples. This is indeed the right formula (see the widget above).
-
If you want to find the mean of normal random variable with known variance , we have . Hence, our KL intuition suggests that estimating up to requires about samples.
-
If you want to find the variance of normal random variable with known mean , we have . Hence, our KL intuition suggests that estimating requires about samples.
In all above cases, it turns out to be the case that our intuition is correct and really describes how many samples you need to solve given problem. In fact, there are two important results in statistics: One of them is Cramér-Rao lower bound that basically says that our formula of is indeed a lower bound. On the other hand, the so-called asymptotic normality theorem for MLE says that the MLE estimator is as good as our formula. 4
The upshot is that computing KL between two close distributions basically answers the most fundamental question of (frequentist) statistics -- how many samples do I need to get a good estimate of a parameter.
Fisher metric
Although KL divergence is asymetrical, it gets symmetrical in the limit. That is, if we do the computation for instead of , we would get the same expression up to some terms. So, in this setup where we try to understand two distributions that are very close together, we can really think of it as being symetric. This way, we can define a proper distance function on the space of distributions -- it's called Fisher information metric and can give useful intuitions. For example, for the case of biased-coin-flipping distributions where coins have bias , we can represent all of them using a segment like this:
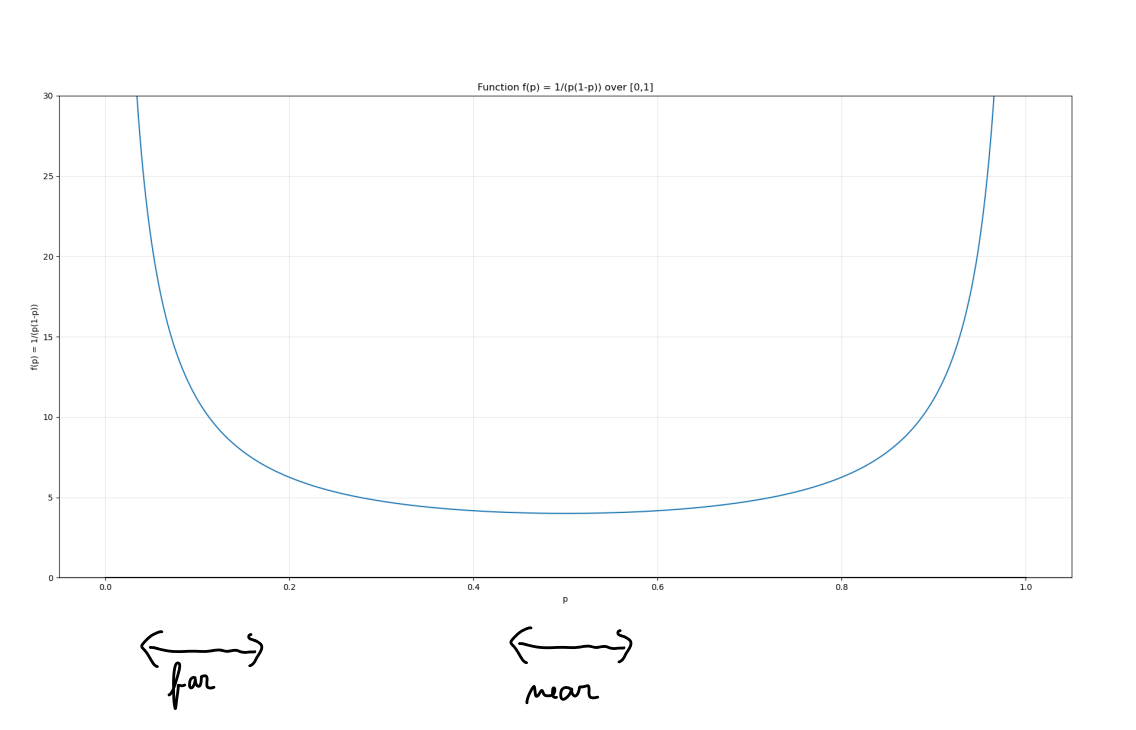
The Fisher information metric says that locally, the KL distance around a point is proportional to . That is, the probabilities around are "closer together" than the probabilities at the edges. This is a supercharged-abstract-fancy way of saying what we have already seen many times -- probabilities should often be handled multiplicatively, not additively.